The third part of the series on information theoretic methods of analysis for dynamic systems is taking longer than anticipated. Crunching the numbers is killing me. So I'll take a break from it and look a little farther forward--how we can use the methods I have been describing so far to forensically examine the algorithms used in various high-frequency trading events of the recent past.
As seen on Nanex and Zero Hedge, there has recently been a lot of strange, algorithmically driven behaviour in the pricing of natural gas and individual stock prices on very short time frames. In an earlier article I pointed out that the apparent simple chaos we observe in the natural gas price appeared to be an emergent property of at least two duelling algorithms.
In this series of articles we will begin analysis of the algorithms involved. Today's discussion will mostly focus on framing the issues that must be addressed in order to study unknown algorithms on the basis of their time-varying outputs. Future articles will present results from the various analyses.
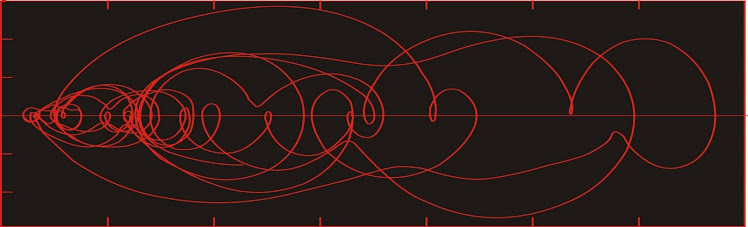
We begin by looking at the activity in the natural gas price on June 8, 2011:

Let us also consider the pricing action in CNTY on June 21, 2011:

Our first assumption is that the bid price and the ask price are being set by competing interests. This assumption is extremely important. It is possible that the bid and the ask are both being set by a single entity, or by two closely related entities who are using them to manipulate the natural gas price. We will go though in some detail the reasoning behind our assumption that there are competing interests involved below.
Secondly, we are approaching this problem assuming that prices are set and changed discontinuously in time rather than continuously in time. Subtleties of this assumption are discussed in the introduction of Bosi and Ragot (2010).
The methodologies we will explore are as follows:
Cross-correlation of the bid and ask series over selected windows. We choose limited time intervals rather than the entire record because we expect that each series will sometimes lead and sometimes follow. Peaks here will show whether one of the series leads or trails the other consistently or whether each one leads intermittently, which would support the idea that these are distinct dueling algorithms. It seems likely that the bid price will lead as both are declining, and the ask will lead as both are climbing. We should test this hypothesis.
One goal of this analysis will be to see if we can detect trigger points, where one stops following and begins leading. We will locate the times and see if the trigger can be identified, which is only likely if the trigger is some change in either price series, the price of a trade, the volume of a trade. Unfortunately, many other triggers are possible, and it may not be possible to identify them if they are, for instance, a random number generator seeded by, say, the thousandths-of-a-second digit at the instant of some distant event like the first pitch of a Yankee's game or when the secretary in the front office misspells 'the'.
Phase space reconstruction--the relevant time series (bid prices, ask prices, trade prices) each represent one-dimensional data sets. If the algorithms used can be visualized in higher-dimensional phase space, we may be able to reconstruct the overall architecture.
The advantage of this approach is that in principle the dynamics of the system will be contained no matter which output of the model we use. We only have measurements of the bid price, but have no idea what other outputs are generated by the same algorithm, even if these unknown outputs are critical to the decision-making module of the algo. The reconstructed phase space
The difficulties here are that 1) the function may change from leader to follower so quickly that the resulting trajectory through phase space is too short to interpret; 2) there may be multiple players on both the bid and ask, meaning the reconstructed trajectory through phase space is an amalgamation of two or more different functions, the instant of joining of which may be impossible to determine; and 3) it may prove impossible to properly define windows for the data, again creating an amalgamation in phases space of two or more different functions.
Epsilon machine reconstruction--We will need to try to identify the actual "work" done by these programs. How do they decide on a price? How do they "decide" to drop or raise their offer? Do they change? How are we to recognize when an algorithm changes its behaviour when all we have to deal with is the output? Can we recognize when the structure of the computation involved in the decision-making part of the algorithm changes, given our extremely limited knowledge of that structure?
These questions may be addressed using the ε-machine reconstruction approach suggested by Crutchfield (1994). The objective of this approach is to use an open-ended modeling scheme to describe the computational structure objectively, so that different practitioners working on the same data will come up with similar (hopefully identical) constructs. By encouraging an heirarchical architecture of undefined complexity, the method allows investigators to identify changes in behaviour of the the system.
This particular approach is built around discrete computation, so is amenable to data which are discrete rather than continuous in time. We assume that the discrete outputs (the time series, or stream of values) is the result of a computational process which is knowable. The data have to be organized, and (this is the key) repeated states are identified. It is possible that these states will be identified from the reconstructed phase space portraits above; alternatively they may be be defined by particular observations. These states may be identified as key strings of data, or may be recognized in complex functions by reconstructing the state space in a higher dimension. The ordering of the states is significant, as the state that appears first before another particular state is referred to as the predictive state, and the following state is the successor state.
The ε-machine is constructed by identifying all the predictive and successor states and calculating the probabilities of all of their observed relationships. If more than one ε-machine is inferred, the sequence of these first-order ε-machines can be used to build a higher-order ε-machine. Given sufficient data, you may construct ε-machines of arbitrary order.
Information theory--as seen in recent articles, information theory may be used to characterize the complexity of the ε-machine reconstruction and the probability density. The yet-to-be completed third part of that series concerns methods of using information theory to find the optimum window length for creating a probability density plot of the reconstructed phase space. The subsequent parts of this series will concern itself with the analyses described above on the nat gas and CNTY algos, as well as others as they are found.
Given the limitations of time and computing resources, I can't guarantee a timeline. I regret that my speed of analysis is six or seven orders of magnitude slower than the incidents in real time.
As seen on Nanex and Zero Hedge, there has recently been a lot of strange, algorithmically driven behaviour in the pricing of natural gas and individual stock prices on very short time frames. In an earlier article I pointed out that the apparent simple chaos we observe in the natural gas price appeared to be an emergent property of at least two duelling algorithms.
In this series of articles we will begin analysis of the algorithms involved. Today's discussion will mostly focus on framing the issues that must be addressed in order to study unknown algorithms on the basis of their time-varying outputs. Future articles will present results from the various analyses.
We begin by looking at the activity in the natural gas price on June 8, 2011:

Let us also consider the pricing action in CNTY on June 21, 2011:

In both of these examples (many more such examples exist) there are three time series of interest to us--the bid price, the ask price, and the prices of trades. Additional information which may also be of use are such things as volume, size of bids, size of asks, and so on. In principal both the bid and ask prices form continuous series which are prone to instantaneous changes. The actual trades form a discontinuous time series with obsrevations at irregular intervals.
We don't have access to the code involved in these algorithms--nevertheless, we can learn something about the computational processes involved, within certain limitations. Unfortunately, just as is the case in studying time series recorded in rocks, we have to make some assumptions, and the validity of our assumptions goes a long way towards predicting the success of our endeavours.
Secondly, we are approaching this problem assuming that prices are set and changed discontinuously in time rather than continuously in time. Subtleties of this assumption are discussed in the introduction of Bosi and Ragot (2010).
The methodologies we will explore are as follows:
Cross-correlation of the bid and ask series over selected windows. We choose limited time intervals rather than the entire record because we expect that each series will sometimes lead and sometimes follow. Peaks here will show whether one of the series leads or trails the other consistently or whether each one leads intermittently, which would support the idea that these are distinct dueling algorithms. It seems likely that the bid price will lead as both are declining, and the ask will lead as both are climbing. We should test this hypothesis.
One goal of this analysis will be to see if we can detect trigger points, where one stops following and begins leading. We will locate the times and see if the trigger can be identified, which is only likely if the trigger is some change in either price series, the price of a trade, the volume of a trade. Unfortunately, many other triggers are possible, and it may not be possible to identify them if they are, for instance, a random number generator seeded by, say, the thousandths-of-a-second digit at the instant of some distant event like the first pitch of a Yankee's game or when the secretary in the front office misspells 'the'.
Phase space reconstruction--the relevant time series (bid prices, ask prices, trade prices) each represent one-dimensional data sets. If the algorithms used can be visualized in higher-dimensional phase space, we may be able to reconstruct the overall architecture.
The advantage of this approach is that in principle the dynamics of the system will be contained no matter which output of the model we use. We only have measurements of the bid price, but have no idea what other outputs are generated by the same algorithm, even if these unknown outputs are critical to the decision-making module of the algo. The reconstructed phase space
The difficulties here are that 1) the function may change from leader to follower so quickly that the resulting trajectory through phase space is too short to interpret; 2) there may be multiple players on both the bid and ask, meaning the reconstructed trajectory through phase space is an amalgamation of two or more different functions, the instant of joining of which may be impossible to determine; and 3) it may prove impossible to properly define windows for the data, again creating an amalgamation in phases space of two or more different functions.
Epsilon machine reconstruction--We will need to try to identify the actual "work" done by these programs. How do they decide on a price? How do they "decide" to drop or raise their offer? Do they change? How are we to recognize when an algorithm changes its behaviour when all we have to deal with is the output? Can we recognize when the structure of the computation involved in the decision-making part of the algorithm changes, given our extremely limited knowledge of that structure?
These questions may be addressed using the ε-machine reconstruction approach suggested by Crutchfield (1994). The objective of this approach is to use an open-ended modeling scheme to describe the computational structure objectively, so that different practitioners working on the same data will come up with similar (hopefully identical) constructs. By encouraging an heirarchical architecture of undefined complexity, the method allows investigators to identify changes in behaviour of the the system.
This particular approach is built around discrete computation, so is amenable to data which are discrete rather than continuous in time. We assume that the discrete outputs (the time series, or stream of values) is the result of a computational process which is knowable. The data have to be organized, and (this is the key) repeated states are identified. It is possible that these states will be identified from the reconstructed phase space portraits above; alternatively they may be be defined by particular observations. These states may be identified as key strings of data, or may be recognized in complex functions by reconstructing the state space in a higher dimension. The ordering of the states is significant, as the state that appears first before another particular state is referred to as the predictive state, and the following state is the successor state.
The ε-machine is constructed by identifying all the predictive and successor states and calculating the probabilities of all of their observed relationships. If more than one ε-machine is inferred, the sequence of these first-order ε-machines can be used to build a higher-order ε-machine. Given sufficient data, you may construct ε-machines of arbitrary order.
Information theory--as seen in recent articles, information theory may be used to characterize the complexity of the ε-machine reconstruction and the probability density. The yet-to-be completed third part of that series concerns methods of using information theory to find the optimum window length for creating a probability density plot of the reconstructed phase space. The subsequent parts of this series will concern itself with the analyses described above on the nat gas and CNTY algos, as well as others as they are found.
Given the limitations of time and computing resources, I can't guarantee a timeline. I regret that my speed of analysis is six or seven orders of magnitude slower than the incidents in real time.
Beautifully Written - I was at ZeroHedge and read this and my first thought was - God, this is beautifully written - I have dyslexia so when I read something that's, that's - I can't explain it all I can say is - Wow, I wish I could write like this..
ReplyDeleteThe economy seems to be getting more unstsble as it runs out of 'growth', like the antics observed when cyclist couriers are stopped at traffic lights but refuse to put their feet on the ground.
ReplyDeleteGood luck with the sums though.