There is an article in the Guardian recently about how humanity should prepare for planetary-scale disasters. The authors offered some suggestions for deciding on the best way for dealing with a disaster, both of which involved setting up panels of experts (government-appointed). The proposals were: 1) setting up a government Office of Risk and Catastrophe; 2) setting up a panel of scientists and experts who would study the problem and advise governments and/or industry the best way to solve it; or 3) setting up two panels of scientists, each of which was to take a contrary position and argue it out--presumably the argument would allow us to see all sides of the problem and thus come up with the best solution.
The one problem that afflicts all of these proposals is the role of government in the funding and in defining the philosophical approach that these panels will take. It appears to be implicit that all of these bodies will be appointed by and accountable to some government, most likely at the national level. The past history of similar panels suggests that politics will play some role in the solutions.
Just as Noam Chomsky and Edward S. Herman explain in Manufacturing Consent: The Political Economy of the Mass Media , any body dependent on government sources for information (or in this case, for funding) will find itself squeezed if it keeps making recommendations that are at odds with current government policy. Furthermore, any of the above solutions can be used to frame the debate by presenting a limited range of options. Even in the third option, it is likely that only two possible courses of action will be proposed, when in fact it may be useful to debate a wide range of possible actions.
, any body dependent on government sources for information (or in this case, for funding) will find itself squeezed if it keeps making recommendations that are at odds with current government policy. Furthermore, any of the above solutions can be used to frame the debate by presenting a limited range of options. Even in the third option, it is likely that only two possible courses of action will be proposed, when in fact it may be useful to debate a wide range of possible actions.
Is there a better way? One method might be a futures market similar to the Pentagon's ill-fated Policy Analysis Market. Although there was popular revulsion to this particular application, the concept of a prediction market is a sound method of allowing information to flow from innovators to the general market.
There are those who would say that a prediction market works on a kind of "hive mind" principle. To me it sounds like superstition. History shows that mobs are not smarter than individuals. I prefer to think that prediction markets work because information is not evenly distributed, however that the profit motive is an efficient means to spread it around (which may foreshadow what I will say below about the efficient-market hypothesis).
As an aside, I once asked an introductory-level statistics class to consider the following problem: you are one of 500 passengers about to board a plane with 500 seats. Each passenger has a boarding card with an assigned seat. As the first passenger boards the plane, he discovers he has lost his boarding card, so he chooses a seat at random and sits in it. All subsequent passengers attempt to take their seats, but if one finds her seat occupied, she will choose an empty seat at random. If you are the last passenger to board the plane, what is the probability that you will be able to sit in your assigned seat (answer below). None of the students in the class had any idea of how to approach this (probably my fault!) so I conducted an experiment. I had everyone guess, tallied up the answers and took the average, which turned out to be surprisingly close to the correct answer. So maybe all of us are smarter than just one of us. (Admittedly, the result was helped by the two exceptional know-nothings who each guessed a probability higher than 1).
What is the basis of my assertion that some participants in, say, the stock market have more information than others? One is the long history of investigations into allegations of insider trading. The other is that an analysis of market dynamics shows that stock price movements have the distinctive fingerprints of this flow of information all over them.
A common problem faced by scientists studying natural systems is that the systems are complex: frequently they are dynamic, driven, and dissipative (meaning that they move, are influenced by energy or matter inputs, and some energy is lost through friction or its equivalent). Such a system may be described by any number of differential equations, and modified by any number of time-varying inputs and boundary conditions. Additionally, the system may have many different outputs, only some of which (commonly only one of which) we actually observe. Naturally we don't know any of the actual equations, nor do we know what the inputs are, nor do we know if the particular observations we have made actually reflect what is happening within the system. Such is the life of a geologist, for instance. Despite these difficulties, we are full of optimism that somehow we can infer the dynamics of the system using our observations, and there are even well-defined mathematical approaches to this general problem.
There are many places to track down the information in the following discussion, but a good place to start is
Analysis of Observed Chaotic Data by H.D.I. Abarbanel (referred hereafter as Abarbanel, 1996). Ergodic theory suggests that dynamic information about the entire system is contained within any time-varying output of the system, so we don't need to worry about whether the particular observations we have chosen to make are important or not--everything we are looking for (simplistically speaking) is in there somewhere. But how do we reveal what may possibly be a multi-dimensional structure when we have a single time series (i.e., one dimensional data)?
One approach is to construct a phase space in multiple dimensions from our single time series. To give credit where credit is due, this concept was first discussed in a classic paper by Packard et al. (1980). The simplest approach is to reconstruct the phase space by plotting the time series against a lagged copy of itself. I will carry out a simple demonstration below.
Using the equations for the famous Lorenz "butterfly"--I will perform this work in Excel to show how easily this can be done, although it can be done better in a proper mathematical plotting package (especially one with 3-D rendering).
We will use the following equations:
xn+1=xn+0.005*10*(yn-xn)
yn+1=yn+0.005*(xn*(28-zn)-yn)
zn+1=zn+0.005*(xn*yn-8/3*zn)
Initial coordinates were (1, 0.5, 0). So in this case, I was using 0.005 as a "time-step". Your mileage may vary. You may use a different value, but then you will have either a more or a less dense looking graph than the one depicted below (which demonstrates x vs y over 4000 values).

Lorenz "butterfly" curve rendered in Excel (as a scatterplot) based on x vs y over 4000 points using the equations and initial condition stipulated above.
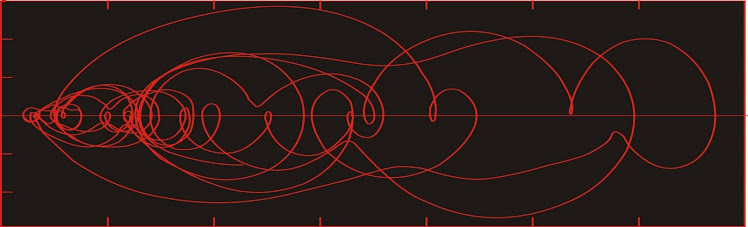
If I were studying the above system, it is possible that the only observations I might have were the x column, which would look like this:
Sequential plot of the first 4000 x-values from the equations and boundary conditions listed above.
They don't look much alike. The first graph is a two-dimensional projection of a three-dimensional object. The graph above is really one-dimensional, and at first glance it does not seem possible to reconstruct the first graph from the second. But if we plot our x-values against a lagged copy (i.e. plot xn vs xn+12), we get:
Reconstructed two-dimensional phase space obtained by the time-delay method, rendered in Excel.
The trick above is to take the data in the x-column, and copy the values (not the formulae) into the next column, starting in the 13th row. You will then have 3988 points defined in two dimensions, which can be plotted on a scatter plot. You may be wondering why I chose the particular lag (why not xn vs xn+100?)--for now consider it to have been an arbitrary decision. There is an information theoretic prescription for deciding on the optimum lag, just as there is a prescription for choosing the correct embedding dimension (I have chosen to use two dimensions because of the limitations of excel, but it would be better to use three).
We see that the reconstructed phase space in two dimensions is topologically very similar to the two-dimensional projection of the actual system. Next time we'll start using this tool to analyze stock charting techniques.
---------
Update - June 19 - did I really forget the answer? Probability of you sitting in your proper seat is 0.5. The easiest way to consider this is to realize that of all the possible random seats that could be selected by the passenger with the missing boarding card, it is only whether he selects his properly assigned seat or yours that matters (as far as our problem is concerned). If he chooses his own seat, you will get to sit in yours; if he chooses yours, then obviously you won't. Any other choice simply defers the critical choice to a later passenger, who will have a smaller selection of seats from which to choose, but will again only have the two meaningful choices.
The one problem that afflicts all of these proposals is the role of government in the funding and in defining the philosophical approach that these panels will take. It appears to be implicit that all of these bodies will be appointed by and accountable to some government, most likely at the national level. The past history of similar panels suggests that politics will play some role in the solutions.
Just as Noam Chomsky and Edward S. Herman explain in Manufacturing Consent: The Political Economy of the Mass Media
Is there a better way? One method might be a futures market similar to the Pentagon's ill-fated Policy Analysis Market. Although there was popular revulsion to this particular application, the concept of a prediction market is a sound method of allowing information to flow from innovators to the general market.
There are those who would say that a prediction market works on a kind of "hive mind" principle. To me it sounds like superstition. History shows that mobs are not smarter than individuals. I prefer to think that prediction markets work because information is not evenly distributed, however that the profit motive is an efficient means to spread it around (which may foreshadow what I will say below about the efficient-market hypothesis).
As an aside, I once asked an introductory-level statistics class to consider the following problem: you are one of 500 passengers about to board a plane with 500 seats. Each passenger has a boarding card with an assigned seat. As the first passenger boards the plane, he discovers he has lost his boarding card, so he chooses a seat at random and sits in it. All subsequent passengers attempt to take their seats, but if one finds her seat occupied, she will choose an empty seat at random. If you are the last passenger to board the plane, what is the probability that you will be able to sit in your assigned seat (answer below). None of the students in the class had any idea of how to approach this (probably my fault!) so I conducted an experiment. I had everyone guess, tallied up the answers and took the average, which turned out to be surprisingly close to the correct answer. So maybe all of us are smarter than just one of us. (Admittedly, the result was helped by the two exceptional know-nothings who each guessed a probability higher than 1).
What is the basis of my assertion that some participants in, say, the stock market have more information than others? One is the long history of investigations into allegations of insider trading. The other is that an analysis of market dynamics shows that stock price movements have the distinctive fingerprints of this flow of information all over them.
A common problem faced by scientists studying natural systems is that the systems are complex: frequently they are dynamic, driven, and dissipative (meaning that they move, are influenced by energy or matter inputs, and some energy is lost through friction or its equivalent). Such a system may be described by any number of differential equations, and modified by any number of time-varying inputs and boundary conditions. Additionally, the system may have many different outputs, only some of which (commonly only one of which) we actually observe. Naturally we don't know any of the actual equations, nor do we know what the inputs are, nor do we know if the particular observations we have made actually reflect what is happening within the system. Such is the life of a geologist, for instance. Despite these difficulties, we are full of optimism that somehow we can infer the dynamics of the system using our observations, and there are even well-defined mathematical approaches to this general problem.
There are many places to track down the information in the following discussion, but a good place to start is
Analysis of Observed Chaotic Data by H.D.I. Abarbanel (referred hereafter as Abarbanel, 1996). Ergodic theory suggests that dynamic information about the entire system is contained within any time-varying output of the system, so we don't need to worry about whether the particular observations we have chosen to make are important or not--everything we are looking for (simplistically speaking) is in there somewhere. But how do we reveal what may possibly be a multi-dimensional structure when we have a single time series (i.e., one dimensional data)?
One approach is to construct a phase space in multiple dimensions from our single time series. To give credit where credit is due, this concept was first discussed in a classic paper by Packard et al. (1980). The simplest approach is to reconstruct the phase space by plotting the time series against a lagged copy of itself. I will carry out a simple demonstration below.
Using the equations for the famous Lorenz "butterfly"--I will perform this work in Excel to show how easily this can be done, although it can be done better in a proper mathematical plotting package (especially one with 3-D rendering).
We will use the following equations:
xn+1=xn+0.005*10*(yn-xn)
yn+1=yn+0.005*(xn*(28-zn)-yn)
zn+1=zn+0.005*(xn*yn-8/3*zn)
Initial coordinates were (1, 0.5, 0). So in this case, I was using 0.005 as a "time-step". Your mileage may vary. You may use a different value, but then you will have either a more or a less dense looking graph than the one depicted below (which demonstrates x vs y over 4000 values).

Lorenz "butterfly" curve rendered in Excel (as a scatterplot) based on x vs y over 4000 points using the equations and initial condition stipulated above.
If I were studying the above system, it is possible that the only observations I might have were the x column, which would look like this:

Sequential plot of the first 4000 x-values from the equations and boundary conditions listed above.
They don't look much alike. The first graph is a two-dimensional projection of a three-dimensional object. The graph above is really one-dimensional, and at first glance it does not seem possible to reconstruct the first graph from the second. But if we plot our x-values against a lagged copy (i.e. plot xn vs xn+12), we get:

Reconstructed two-dimensional phase space obtained by the time-delay method, rendered in Excel.
The trick above is to take the data in the x-column, and copy the values (not the formulae) into the next column, starting in the 13th row. You will then have 3988 points defined in two dimensions, which can be plotted on a scatter plot. You may be wondering why I chose the particular lag (why not xn vs xn+100?)--for now consider it to have been an arbitrary decision. There is an information theoretic prescription for deciding on the optimum lag, just as there is a prescription for choosing the correct embedding dimension (I have chosen to use two dimensions because of the limitations of excel, but it would be better to use three).
We see that the reconstructed phase space in two dimensions is topologically very similar to the two-dimensional projection of the actual system. Next time we'll start using this tool to analyze stock charting techniques.
---------
Update - June 19 - did I really forget the answer? Probability of you sitting in your proper seat is 0.5. The easiest way to consider this is to realize that of all the possible random seats that could be selected by the passenger with the missing boarding card, it is only whether he selects his properly assigned seat or yours that matters (as far as our problem is concerned). If he chooses his own seat, you will get to sit in yours; if he chooses yours, then obviously you won't. Any other choice simply defers the critical choice to a later passenger, who will have a smaller selection of seats from which to choose, but will again only have the two meaningful choices.
{kind=link}
No comments:
Post a Comment